본 게시글의 코드는 https://wikidocs.net/22881 를 참고했음을 밝힙니다.
선형 회귀 알고리즘이 공부한 시간에 따라 변하는 성적, 역까지의 거리에 따라 달라지는 집값 등의 수치를 분석하고 예측하는 알고리즘이었다면, 로지스틱 회귀는 점수가 주어질 때 합격인지 불합격인지, 또는 어떤 메일이 스팸 메일인지 정상 메일인지를 구분하는지와 같은 분류 알고리즘이다. 이렇게 둘 중 하나를 결정하는 문제를 이진 분류(Binary Classification)이라 하고, 셋 이상이면 다중 분류(Multiclass Classification)이라 한다. 다중 분류는 다른 회귀 분석 방법이므로 우선은 넘어가자.
이진 분류
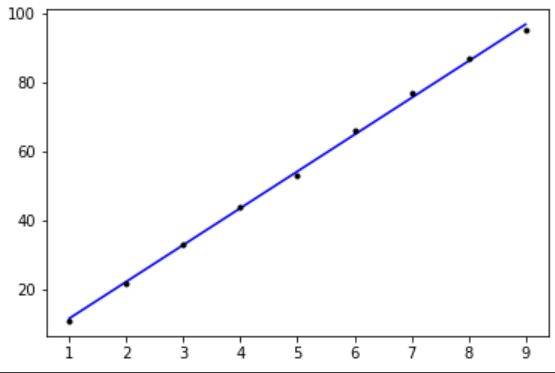
이진 분류 문제는 직선으로 나타내는 것이 적절하지 않다는 것은 아래 그래프만 봐도 알 수 있다.

출처:https://wikidocs.net/22881
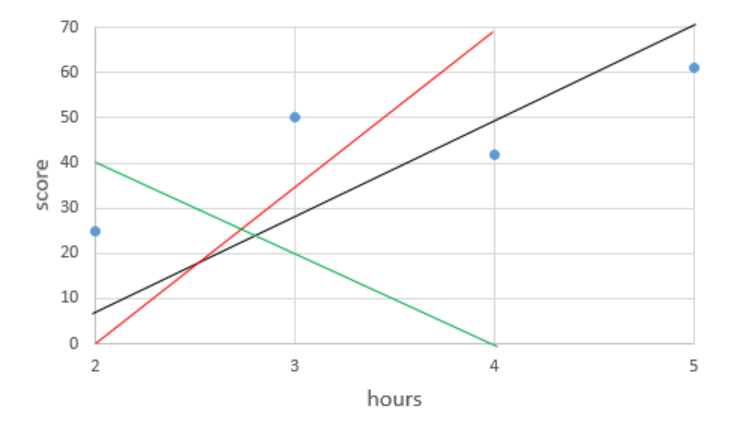
합격을 1, 불합격을 0이라 하고 55점까지는 불합격, 60점부터는 합격이라는 것을 도식화한 것이다. 누가 봐도 직선은 아니다. 애초에 직선으로 도식화하기 불가능하다. 분류 문제는 그래서 선형 회귀 분석 방법을 쓰지 못한다. 또, 직선의 경우 음의 무한대부터 양의 무한대와 같은 값도 갖기 때문에 분류 문제에 적합하지 않다.
근데 위와 같은 그래프의 경우는, 직선은 아니나 선형함수의 형태로 그래프가 그려져 있는데 이러면 분류 작업이 제대로 작동하지 않는다.(왜 그런지는 딥러닝 챕터: 활성화 함수에서 후술)
따라서, 이러한 직선 형태를 s자 모양의 곡선 형태로 바꾸어주어야 하는데, 이를 시그모이드 함수(Sigmoid Function)이라고 한다.
시그모이드 함수

출처:https://wikidocs.net/22881
출력이 0과 1의 값을 가지면서 곡선 형태를 갖는 함수이다.
저 그림 그대로 출력하는 코드는 아래와 같다.

7번째 줄과 11번째 줄 왜 저렇게 되는지 모르겠지만 일단 코드는 이렇다.
시그모이드 함수도 선형 회귀와 마찬가지로 적합한 w,b값을 찾아내는 것이 목적이다. 그렇다면 가중치 w와 b에 따라 시그모이드 기본 형태가 어떻게 달라지는지를 살펴보고, 그것을 구현하는 코드는 어떻게 되어있는지 살펴보자.
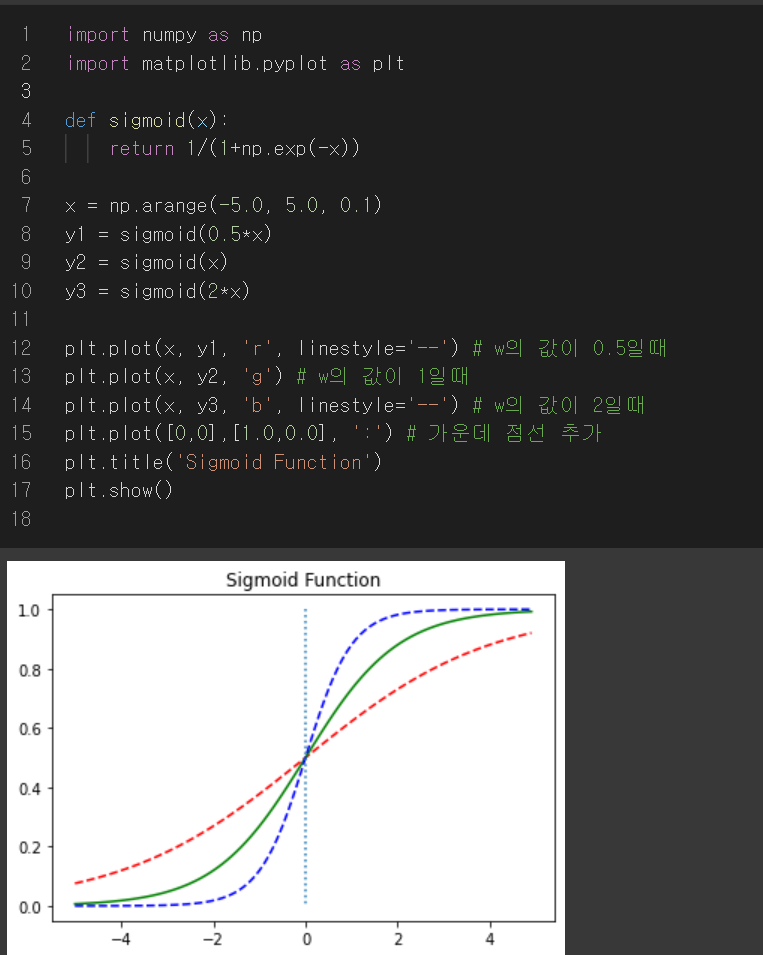
w값이 달라짐에 따라 시그모이드 함수의 경사가 달라지며, 코드는 위와 같이 변경한다. 빨간 점선이 8,12번째 줄, 초록 선(기본형)이 9,13번째, 파란 점선이 10,14번째 줄에 대응이 된다. 위 결과를 보고 w값이 커질수록 경사가 커지고, w값이 작아질수록 경사도 작아짐을 알 수가 있다.

이번에는 b값이 달라짐에 따라 시그모이드 함수가 y축 방향으로 이동하는 것을 볼 수 있다.
w와 b의 값에 따라 시그모이드 기본형 함수에서의 결과와 전혀 다른 결과가 도출되므로 적절한 w,b의 값을 찾는 것이 아주 중요하다
시그모이드 함수는 입력값이 커질수록 1에 수렴, 입력값이 작아질수록 0에 수렴한다. 0.5이상이면 1, 그 이하면 0으로 간주했을 때 0과 1로 분류(즉, 이진 분류)가 되기 때문에 이진 분류 문제를 풀 수 있는 것이다.
'인공지능(ML) > 딥러닝' 카테고리의 다른 글
| [딥러닝] Tensorflow로 간단한 Linear regression 알고리즘 구현 (0) | 2024.01.04 |
|---|---|
| 코드 실습: 선형 회귀(케라스) (0) | 2023.09.16 |
| 코드 실습: 선형 회귀(텐서플로우) (0) | 2023.09.16 |
| 최적화 알고리즘: 경사하강법 (0) | 2023.09.16 |
| 비용함수를 쓰는 이유 (0) | 2023.09.16 |